Web Crawler System Design
Web Crawler System Design - The brute force solution would be that this node communicates with all other nodes to see what are the. Web a web crawler, an internet bot, systematically searches the web for content, starting with seed urls. They wander around the web. Web written by former meta and amazon interviewers, this guide breaks down the core concepts, patterns, frameworks, and technologies needed to ace your system design. Let's design a web crawler that will systematically browse and download the world wide web. Web web crawling or web indexing is a program that collects webpages on the internet and stores them in a file, making them easier to access. The crawler scales to (at least) several hundred. Get an overview of the building blocks and components of the web crawler system, and learn about the interaction that takes place between them during the. Web the system to design. Web a web crawler is an internet bot that systematically scours the world wide web (www) for content, starting its operation from a pool of seed urls. Web a web crawler is an internet bot that systematically scours the world wide web (www) for content, starting its operation from a pool of seed urls. Don’t forget to get your copy of designing data intensive applications, the single most important book to read for system design interview prep!. This process, known as crawling, stores the acquired content. Refer. All budgets catered forresponsive web designfree quotes fastsee ratings & reviews A robust development environment is the foundation of any successful project. This process, known as crawling, stores the acquired content. Get an overview of the building blocks and components of the web crawler system, and learn about the interaction that takes place between them during the. Web crawling —. The crawler should also be expandable to other media and. After a node crawls a page, it will get a list of urls to crawl next. A web crawler, or spider, is responsible for trawling the internet and indexing the pages that reside there. Refer to the linked content for general talking. Don’t forget to get your copy of designing. Get an overview of the building blocks and components of the web crawler system, and learn about the interaction that takes place between them during the. The crawler scales to (at least) several hundred. Web written by former meta and amazon interviewers, this guide breaks down the core concepts, patterns, frameworks, and technologies needed to ace your system design. Pic. A robust development environment is the foundation of any successful project. Consulte nuestras tarifasappsintegrated softwareeasy to use Web design a web crawler. A web crawler, or spider, is responsible for trawling the internet and indexing the pages that reside there. Let's design a web crawler that will systematically browse and download the world wide web. Welcome to day 12 of system design case studies series where we will design web crawler, google. Web system design (hld) for a web crawler by a faang senior engineer that has reviewed over 100 design documents. The crawler scales to (at least) several hundred. Web the system to design. They wander around the web. Web the system to design. The output of the crawling process is the data that’s the. Web web crawling or web indexing is a program that collects webpages on the internet and stores them in a file, making them easier to access. Web designing a web crawler. This process, known as crawling, stores the acquired content. The crawler scales to (at least) several hundred. Web the system to design. The brute force solution would be that this node communicates with all other nodes to see what are the. Get an overview of the building blocks and components of the web crawler system, and learn about the interaction that takes place between them during the. Welcome to. The crawler scales to (at least) several hundred. This document links directly to relevant areas found in the system design topics to avoid duplication. Web system design (hld) for a web crawler by a faang senior engineer that has reviewed over 100 design documents. Web designing a web crawler. They wander around the web. Once it is fed with the initial. This process, known as crawling, stores the acquired content. The crawler should also be expandable to other media and. A robust development environment is the foundation of any successful project. Web written by former meta and amazon interviewers, this guide breaks down the core concepts, patterns, frameworks, and technologies needed to ace your. Request a free demodigitally accessibledemo: The crawler scales to (at least) several hundred. Web designing a web crawler. Web the system to design. Web preparing your development environment. This document links directly to relevant areas found in the system design topics to avoid duplication. The output of the crawling process is the data that’s the. Consulte nuestras tarifasappsintegrated softwareeasy to use Web a web crawler, an internet bot, systematically searches the web for content, starting with seed urls. Web the architecture of a web crawler: They wander around the web. Don’t forget to get your copy of designing data intensive applications, the single most important book to read for system design interview prep!. This process, known as crawling, stores the acquired content. Web web crawling or web indexing is a program that collects webpages on the internet and stores them in a file, making them easier to access. Once it is fed with the initial. Pic copyright and credits :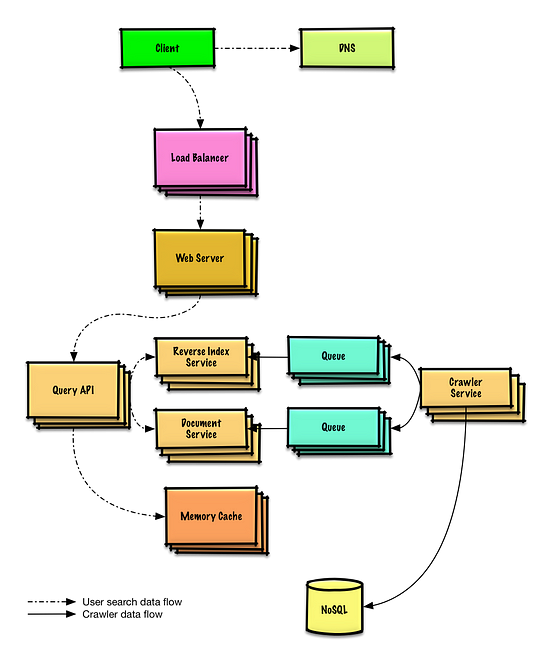
Making Web Crawler and Scraper The Easy Way by Suchana Chakrabarti
Design Distributed Web Crawler

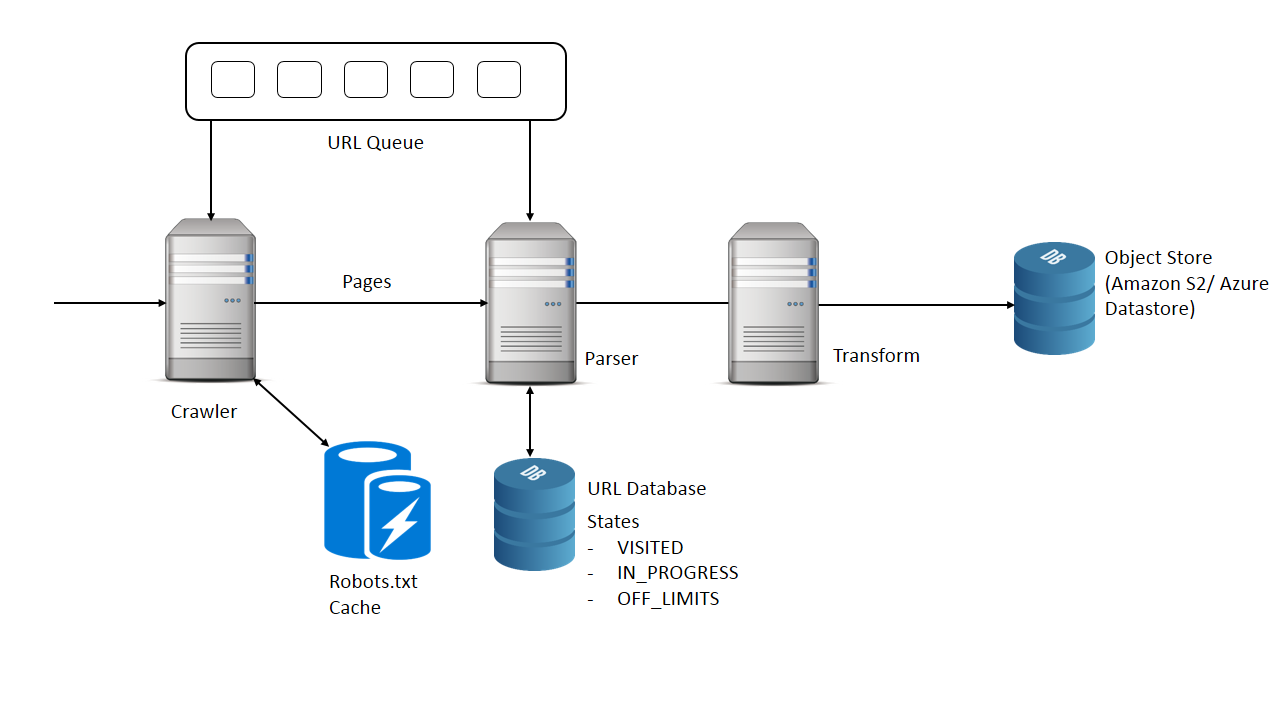
Web Crawler Architecture Download Scientific Diagram
Exploring the Architecture of Web Crawlers A Comprehensive Guide
Web Crawler System Design

System Design distributed web crawler to crawl Billions of web pages
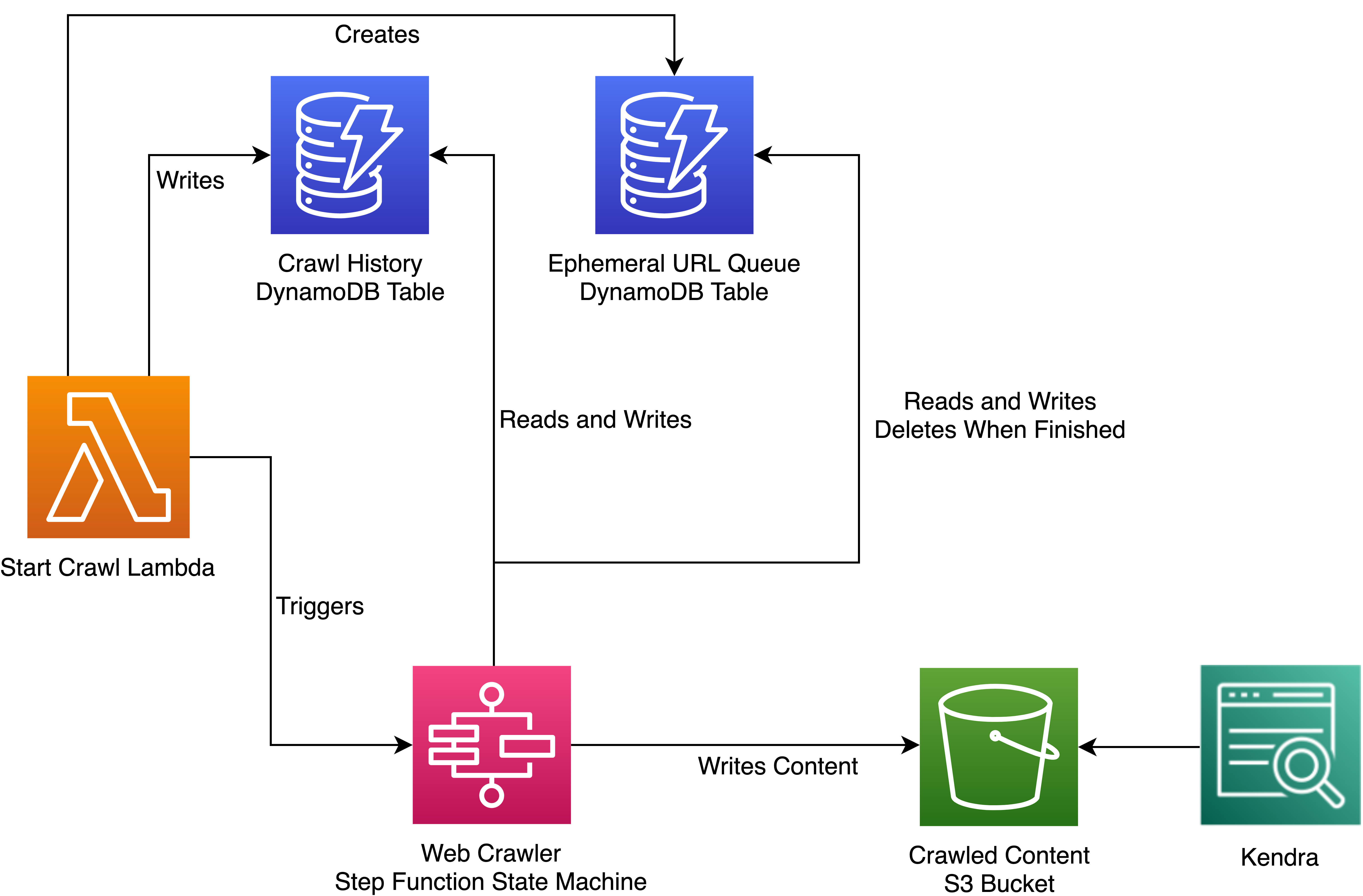
Scaling up a Serverless Web Crawler and Search Engine AWS
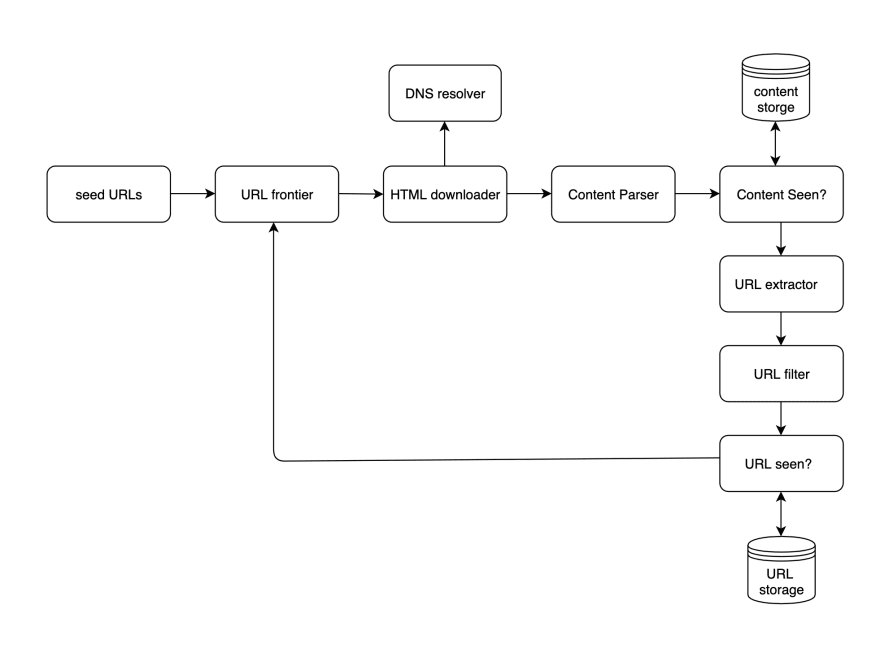
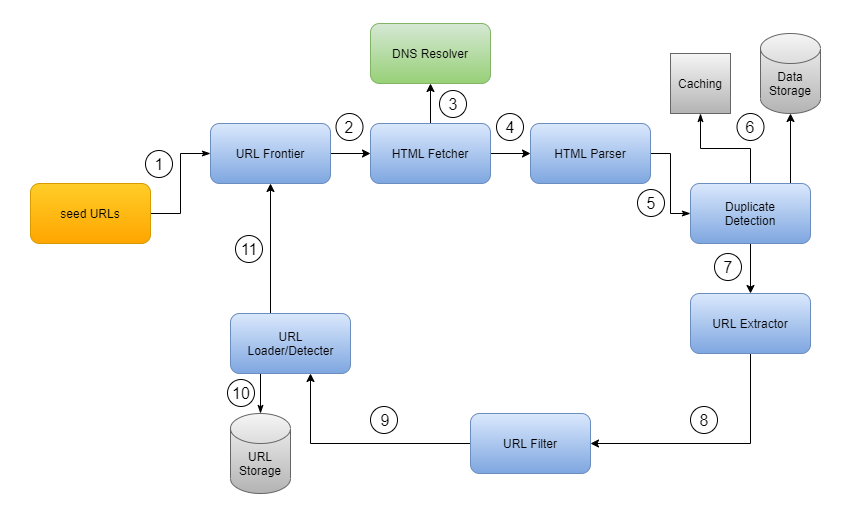
Design a Web Crawler DEV Community
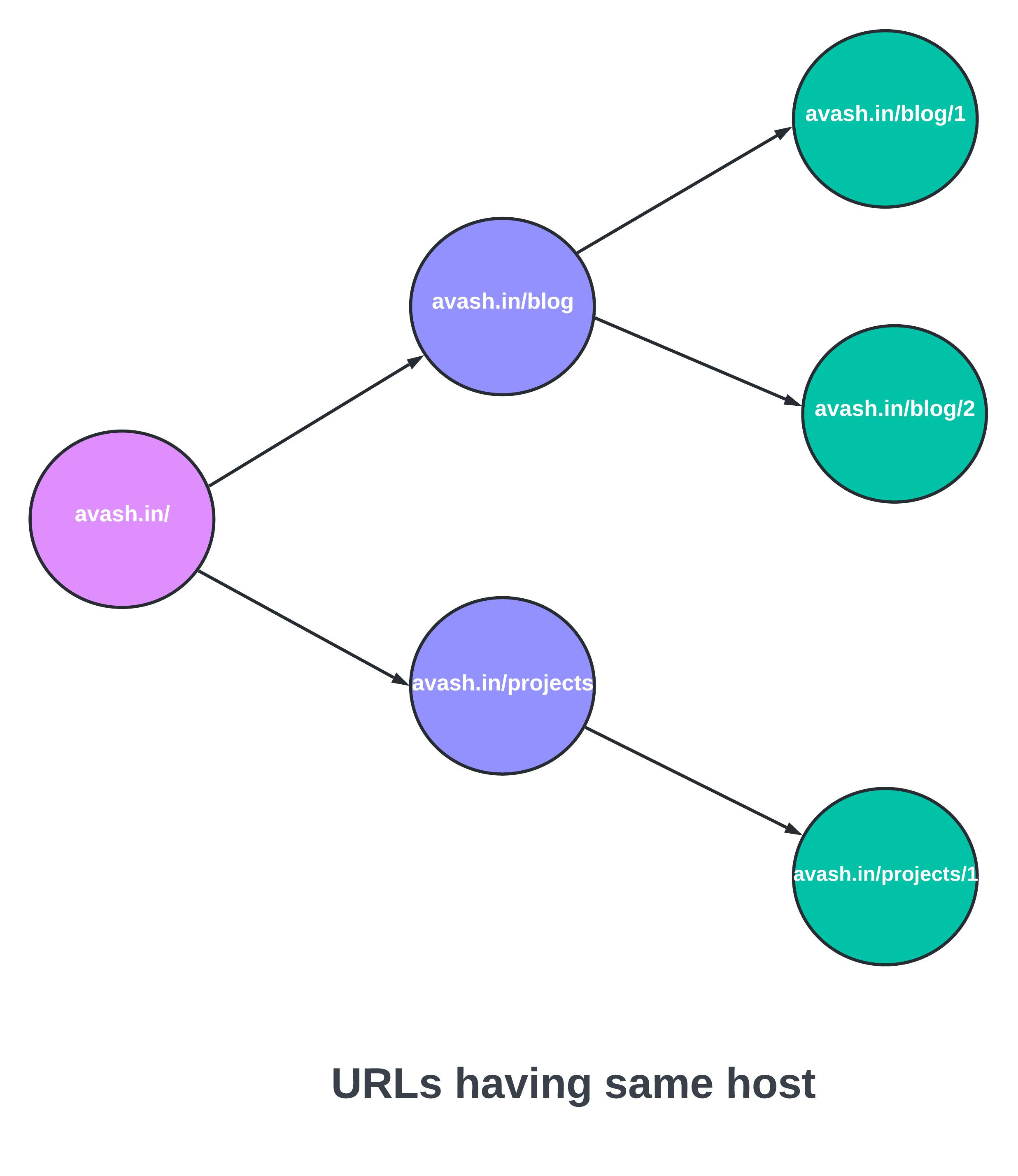
10 Typical highlevel architecture of a Web crawler, involving a

Design Web Crawler The Road To Architect
Web Crawling — The System Is Designed To Search The World Wide Web, Starting With A List Of Seed Urls Initially Provided By The System Administrator.
After A Node Crawls A Page, It Will Get A List Of Urls To Crawl Next.
Welcome To Day 12 Of System Design Case Studies Series Where We Will Design Web Crawler, Google.
Web A Web Crawler Is An Internet Bot That Systematically Scours The World Wide Web (Www) For Content, Starting Its Operation From A Pool Of Seed Urls.
Related Post: