System Design Web Crawler
System Design Web Crawler - Outline use cases and constraints. An interesting and classic system design interview question. Web when designing a web crawler system, we should consider some important characteristics: This process, known as crawling, stores the acquired content for subsequent use. Web crawlers are also known as web spiders, robots, worms, walkers, and bots. In other words, a web crawler should efficiently handle this task using parallelization. Gather requirements and scope the problem. Written by former meta and amazon interviewers, this guide breaks down the core concepts, patterns, frameworks, and technologies needed to ace your system. Everything you need to quickly get prepared for faang system design interviews. Let's design a web crawler that will systematically browse and download the world wide web. In other words, a web crawler should efficiently handle this task using parallelization. Gather requirements and scope the problem. System should be scalable because there are billions of web pages that need to be crawled and analyzed. A web crawler is known as a robot or spider. Web a web crawler, an internet bot, systematically searches the web for content,. It collects documents by recursively fetching links from a set of starting pages. Web designing a web crawler. It is widely used by search engines to discover new or updated content on the web. We’ll explore the main parts and design choices of such a system in this article. Let's design a web crawler that will systematically browse and download. Web a web crawler is a software program which browses the world wide web in a methodical and automated manner. Outline use cases and constraints. In other words, a web crawler should efficiently handle this task using parallelization. Gather requirements and scope the problem. It collects documents by recursively fetching links from a set of starting pages. It is widely used by search engines to discover new or updated content on the web. Web in this chapter, we focus on web crawler design: It collects documents by recursively fetching links from a set of starting pages. Web crawlers are also known as web spiders, robots, worms, walkers, and bots. Everything you need to quickly get prepared for. Web when designing a web crawler system, we should consider some important characteristics: This process of acquiring content from the www is called crawling. It is widely used by search engines to discover new or updated content on the web. Web creating a web crawler system requires careful planning to make sure it collects and uses web content effectively while. Web design a web crawler. Gather requirements and scope the problem. Outline use cases and constraints. Web creating a web crawler system requires careful planning to make sure it collects and uses web content effectively while being able to handle large amounts of data. This document links directly to relevant areas found in the system design topics to avoid duplication. Outline use cases and constraints. Web design a web crawler. Web in this chapter, we focus on web crawler design: System should be scalable because there are billions of web pages that need to be crawled and analyzed. Refer to the linked content for general talking points, tradeoffs, and alternatives. We’ll explore the main parts and design choices of such a system in this article. It collects documents by recursively fetching links from a set of starting pages. Web designing a web crawler. It is widely used by search engines to discover new or updated content on the web. Refer to the linked content for general talking points, tradeoffs, and. Web a web crawler is an internet bot that systematically scours the world wide web (www) for content, starting its operation from a pool of seed urls. It is widely used by search engines to discover new or updated content on the web. In other words, a web crawler should efficiently handle this task using parallelization. Web design a web. An interesting and classic system design interview question. Web when designing a web crawler system, we should consider some important characteristics: Gather requirements and scope the problem. Web designing a web crawler. In other words, a web crawler should efficiently handle this task using parallelization. System should be scalable because there are billions of web pages that need to be crawled and analyzed. The output of the crawling process is the data that’s the input for the subsequent processing phases—data cleaning, indexing, page relevance using algorithms like page ranks, and analytics. Web a web crawler, an internet bot, systematically searches the web for content, starting with seed urls. This document links directly to relevant areas found in the system design topics to avoid duplication. A web crawler is known as a robot or spider. Web crawlers are also known as web spiders, robots, worms, walkers, and bots. Web creating a web crawler system requires careful planning to make sure it collects and uses web content effectively while being able to handle large amounts of data. We’ll explore the main parts and design choices of such a system in this article. It collects documents by recursively fetching links from a set of starting pages. This process, known as crawling, stores the acquired content for subsequent use. Gather requirements and scope the problem. Web in this chapter, we focus on web crawler design: Web designing a web crawler. Written by former meta and amazon interviewers, this guide breaks down the core concepts, patterns, frameworks, and technologies needed to ace your system. Web design a web crawler. Web a web crawler is a software program which browses the world wide web in a methodical and automated manner.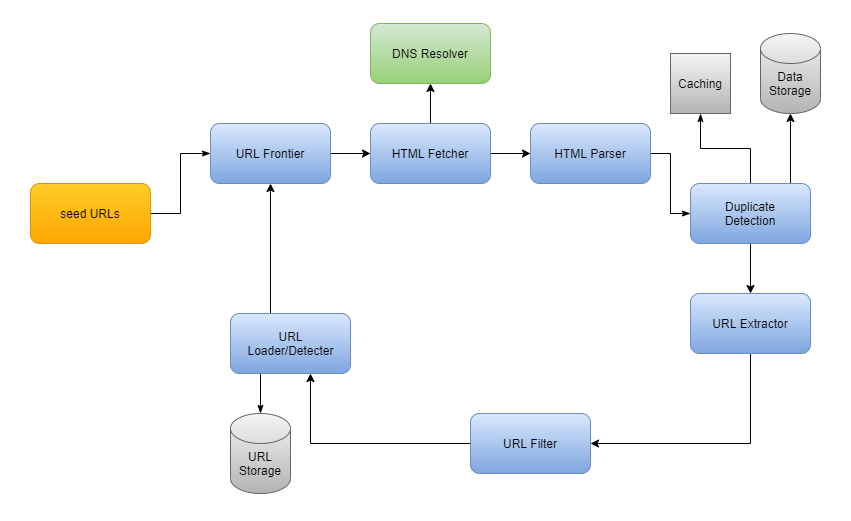
Web Crawler System Design

System Design Web Crawler (Amazon Interview Question) YouTube
10 Typical highlevel architecture of a Web crawler, involving a

Web Crawler Architecture Download Scientific Diagram

Design Web Crawler The Road To Architect
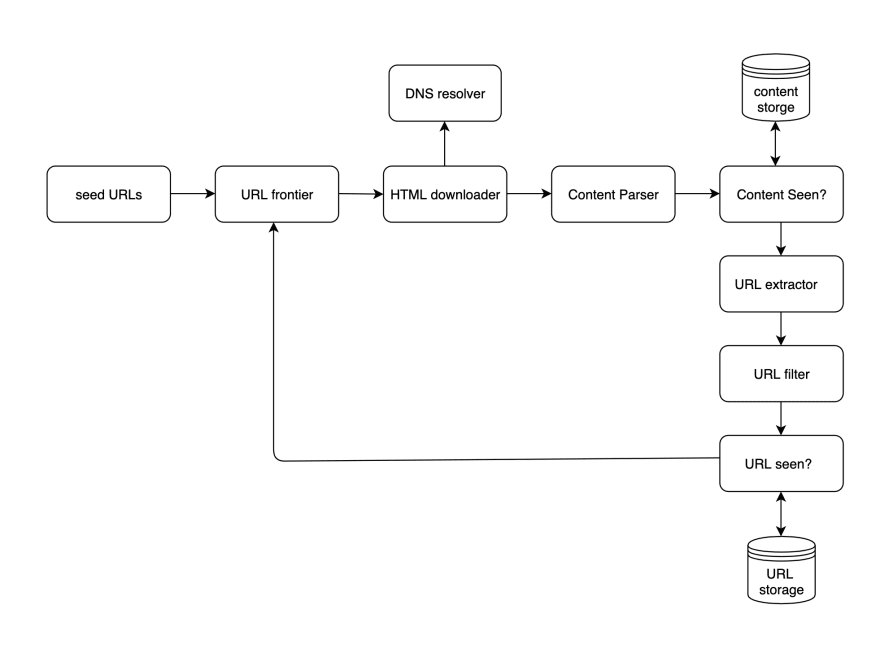
Design a Web Crawler DEV Community
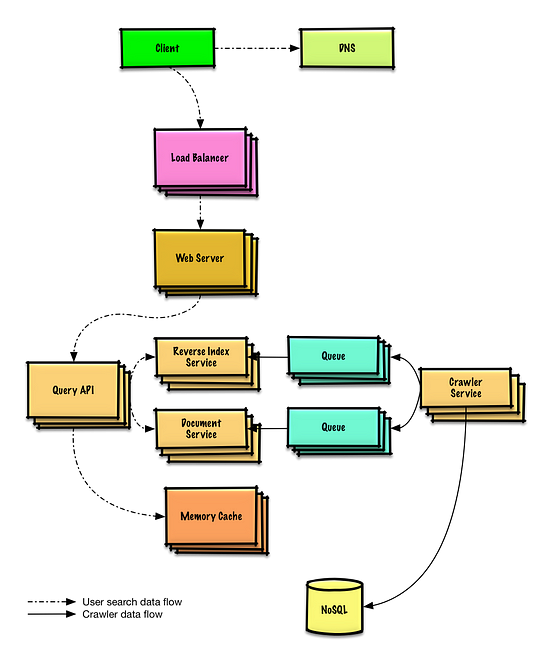
Making Web Crawler and Scraper The Easy Way by Suchana Chakrabarti

Scaling up a Serverless Web Crawler and Search Engine AWS

System Design distributed web crawler to crawl Billions of web pages
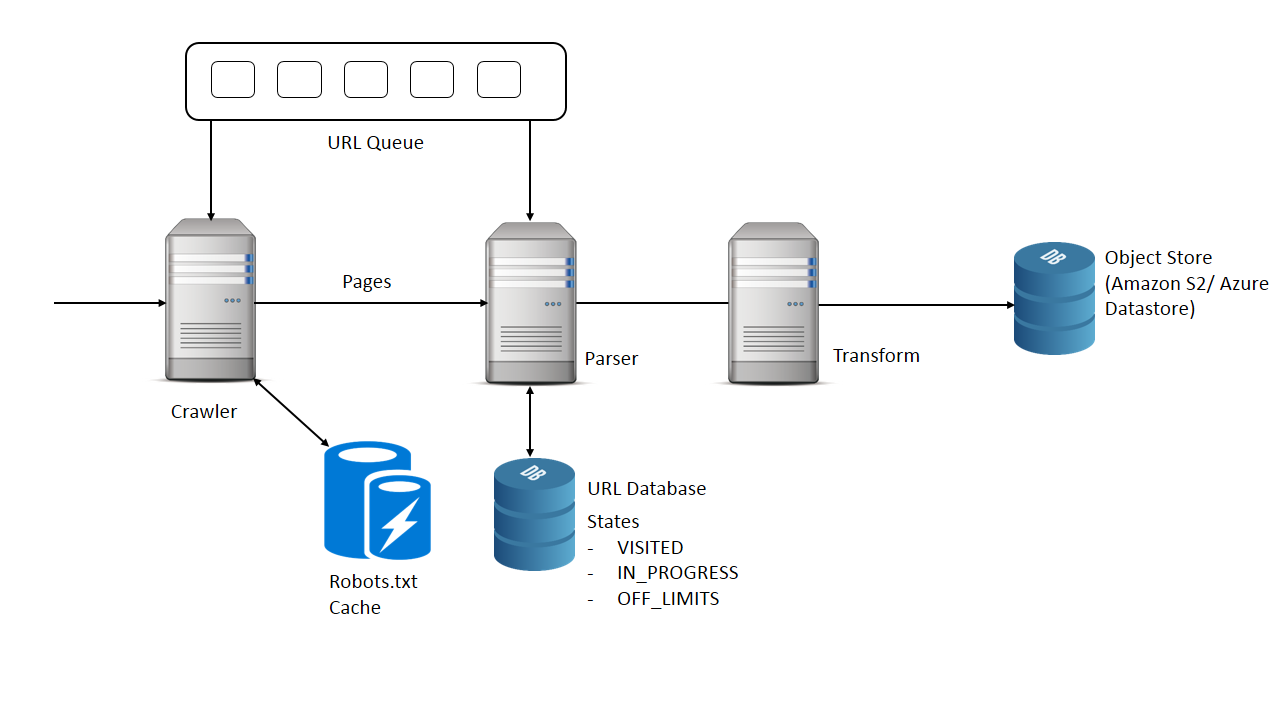
Design Distributed Web Crawler
It Is Widely Used By Search Engines To Discover New Or Updated Content On The Web.
Web When Designing A Web Crawler System, We Should Consider Some Important Characteristics:
This Process Of Acquiring Content From The Www Is Called Crawling.
Refer To The Linked Content For General Talking Points, Tradeoffs, And Alternatives.
Related Post: